


We are now taking the next steps in the democratization and value creation of Large Language Models...
How we work with training data for GPT-SW3
 Photo by Lysander Yuen on Unsplash
Photo by Lysander Yuen on Unsplash
This post describes the work done by the NLU research group at AI Sweden to collect and process training data for the GPT-SW3 language model. We call the resulting dataset The Nordic Pile.
As we have described in our previous posts [1, 2], we develop GPT-SW3 in order to produce a foundational resource for Swedish (and Nordic) NLP, and to investigate the practical usefulness of large generative models for solving real-world NLP tasks. Our hope is that the model will be useful across a variety of different application domains and use cases, ranging from academic research to applications in both the public and private sectors.
We know from previous research that foundation models need to be large both with respect to the number of parameters in the model, and also with respect to the amount of training data that the model has seen. Since our goal is to develop a model that can be as representative as possible of the Swedish-speaking population, we aim for a final model with more than 100 billion parameters, and we aim to use training data that as closely as possible reflects the dialects, sociolects, demography and interests of the Swedish citizens.
One challenge (among many) with such an ambition is that Swedish is a relatively small language with a relatively limited number of speakers. This means that there are limited amounts of text data available in Swedish, in particular when it comes to readily available datasets. For NLP in Swedish, the main source of data is Språkbanken Text which provides a range of NLP datasets, but most are relatively small, and some are sentence-scrambled which limits their usefulness for training language models. We can also mention the National Library of Sweden which collects and stores all text published in Sweden. Unfortunately, this rich and valuable source of data is not available for external NLP research and development (we did contact the National Library with a request to collaborate on GPT-SW3, but they were not willing to share their data with this project).
The Nordic Pile
Since there are no readily available large-scale collections of Swedish text data, it has been necessary for us to compile our own dataset, based primarily on existing data sources such as OSCAR, MC4, and OPUS. We have also collected data from repositories such as DiVA, FASS, the Swedish government’s open data portal, 1177, Wikipedia, Litteraturbanken, as well as websites of Swedish authorities, and some of the largest Swedish discussion forums such as Flashback, Familjeliv, and Swedish discussions on Reddit.
In addition to this, we have also relied on the fact that Swedish is part of a relatively small family of languages (the North Germanic language group) that includes Norwegian, Danish, Icelandic, and Faroese. We therefore also include existing datasets in these languages, except for Faroese where we were not able to find any data. Examples of datasets in these languages include the before-mentioned OSCAR, MC4, OPUS, Wikipedia, and Reddit data sources, as well as the Norwegian Colossal Corpus, the Danish Gigaword Corpus, and the Icelandic Gigaword Corpus. We also include a sample of English data from The Pile as well as programming code collected from CodeParrot. Lastly, we also include a special mathematics dataset in both Swedish and English, since we are interested in investigating the extent to which the model will be able to perform simple math.
The resulting dataset, which we call the Nordic Pile, amounts to approximately 1.3 TB of data in total, and has the following distribution over languages:
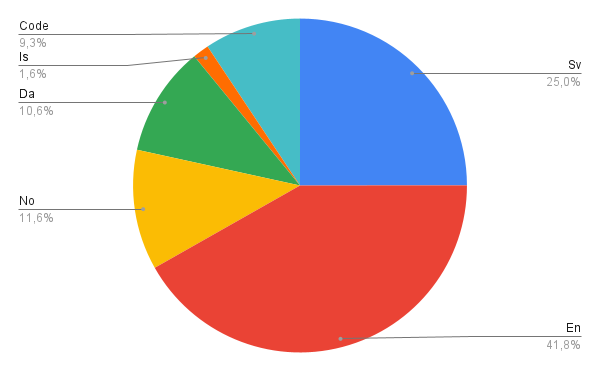
In addition to being sufficiently large for training a multi-billion parameter language model, the Nordic Pile dataset also contains a rich typological variety that we hypothesize will be useful for the model’s performance in all of the Nordic languages. However, the language distribution of the original data may be somewhat suboptimal if the goal is to build a primarily Swedish, and secondarily Nordic language model. We therefore weigh the different languages to better reflect our end goal, and we also weigh the various data sources to better reflect our ambition to arrive at a representative model for the Swedish population. This weighting of data sources includes down-weighting web crawled data, which is known to be noisy and of relatively low quality, and up-weighting high-quality editorial sources such as Wikipedia. We also deduplicate our data by using both exact deduplication (i.e. removing copies of the same content), and fuzzy deduplication, where we use Locality-Sensitive Hashing (LSH) to remove content that is very similar to other content on the dataset. The final version of the Nordic Pile that we use as training data for GPT-SW3 consists of the following distribution of languages:
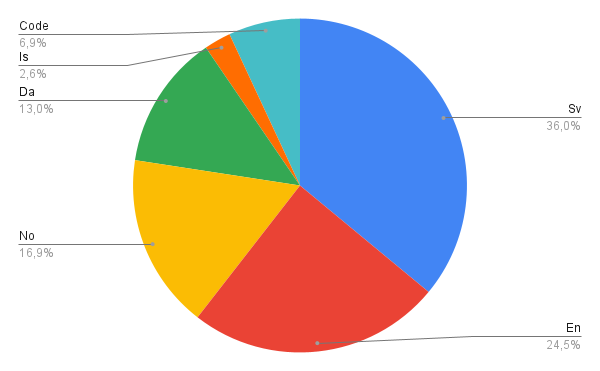
Ethical and legal considerations
Our main guiding principles when collecting the Nordic Pile has been to ensure that the data is both representative and of high quality, while at the same time being of sufficient quantity to enable training of large language models. To ensure that the models can generalize over a variety of different domains and that they are useful for a range of different applications, we have tried to collect texts that are representative of a variety of language styles and usages, knowledge domains, and social groups. The mix of editorial sources, such as newspaper articles or texts published on the homepages of governmental authorities and public sector organizations, and user-generated content such as blogs and forums assures a wide range of both styles and topics.
Since most of the datasets in the Nordic Pile are too big to allow for careful manual quality inspection, we instead rely on programmatic rules for quality assurance that follow best practices from the research literature. Decisions on which datasets to include and which to exclude were taken collectively by the GPT-SW3 development team after thorough discussions about the advantages, disadvantages, and risks of the various datasets. Advantages and disadvantages relate primarily to the quality of the text sources regarding technical processability. For example, the SOU dataset (Statens offentliga utredningar) contains text extracted from PDFs, but because of the pitfalls of PDF text extraction, this dataset was eventually dismissed. Another reason for dismissing datasets is the occurrence of computer-generated texts, which was the case e.g. for a dataset containing subtitles from YouTube.
We have also mapped a number of potential risks using the Nordic Pile dataset. Most of these relate primarily to text sources that we know contain, or that are very likely to contain, large amounts of personal information. To filter such material, we selected certain social discussion subforums and defined a list of websites that shall not be included in the training data: these include, for example, hitta.se and eniro.se, i.e. websites that collect information about individuals such as address, telephone number, birthday, persons living in the same household etc. from official registers and telecom operators. We also perform anonymization as a measure to support the rights of data subjects potentially present in the text data collected from online forums. For discussion forums (Flashback and Reddit) we anonymize all user names by exchanging them with randomly sampled names compiled from name lists by SCB (and other national equivalents).
Another risk that we identified relates to discriminatory language and hate speech present in online discourses and thus in the Nordic Pile. In this case, we decided not to filter our datasets. This decision comes with potential upsides and downsides. On the upside, we believe that not aggressively content filtering the training data will lead to a more versatile model that can be used as a foundational resource for a broad set of NLP tasks — including, for example, the detection and analysis of discrimination and hate speech at scale in the context of research or content moderation. The downside is that the model will be able to reproduce the problematic content and thus reinforce discrimination and hate speech present in today’s online discourses. Our decision shifts the focus to the responsible use of the model, and it increases the need for clear usage guidelines and safety checks when building applications based on the model.
To tackle these issues, we are currently establishing a Subject Matter Expert Pool. This expert pool consists of researchers from the humanities and social sciences who have profound knowledge of the social and cultural contexts in which the texts of our training data have been produced. Together with them, we will address questions of representativeness, fairness and discrimination as well as “undesired” model outputs in concrete use case scenarios. We aim to iteratively re-evaluate our decisions on filtering.
In our work with the Nordic Pile, we have made significant efforts to both comply with GDPR and at the same time ensure that the data contains as representative and diverse content as possible in order to arrive at a model that reflects the entire Swedish society. It is clear that we will not be entirely successful in this. The training data for GPT-SW3 is probably quite representative of Swedish internet discourse in general, and of the Swedish public sector, but we know that this data does not necessarily reflect the entire Swedish population. On the other hand, it is not clear if it would be at all possible to collect such data that would be completely representative of a population. Given the limited resources available to us in the GPT-SW3 initiative, we have done our best to make sure that our data collection and processing efforts have been as responsible and transparent as possible, while at the same time being open to reassessing and restructuring our plan and workflow based on new evidence and input. Our overarching goal remains to produce a language model that can be a foundational resource for Swedish and Nordic NLP.

